AI PC时代新基准到来!英特尔Panther Lake图像处理单元及无线子系统技术解析
2023年以来,生成式AI负载逐步从云端下沉到终端,英特尔率先提出“AI PC”概念,为AI PC确立了算力基准,并在Meteor-Lake、Lunar-Lake两代产品上完成生态验证。
2026年1月CES,英特尔将发布第三代酷睿Ultra家族——Panther Lake(PTL),以18A先进工艺制程、RibbonFET+PowerVia、Foveros-S2.5D高阶封装重构客户端SoC。
本文聚焦其Xe3-LPG集成显卡与Wi-Fi 7R2无线子系统,分析架构级改进,以及图形性能与连接上的巨大升级,在CES 2026前夕来和大家共同探讨一下,英特尔的Panther Lake如何能在2026-2027年为AI PC硬件确立全新的标准。

英特尔Xe3架构:把“独显级”性能塞进移动端
早在去年的Lunar Lake架构上,我们就已经见识到了英特尔使用Xe2架构下的GPU的强大性能表现,让我们在便携轻薄本上流畅运行3A大作,并且整个SoC的功耗也不过30W,带来极为优秀的能耗比表现,并且也将轻薄本的AI算力推向了一个新的高度。

这一次Panther Lake将会采用全新一代的Xe3架构,采用了和独立显卡一样的架构设计,在性能表现上,相对于上代的锐炫Xe2架构有了更加明显的性能提升。



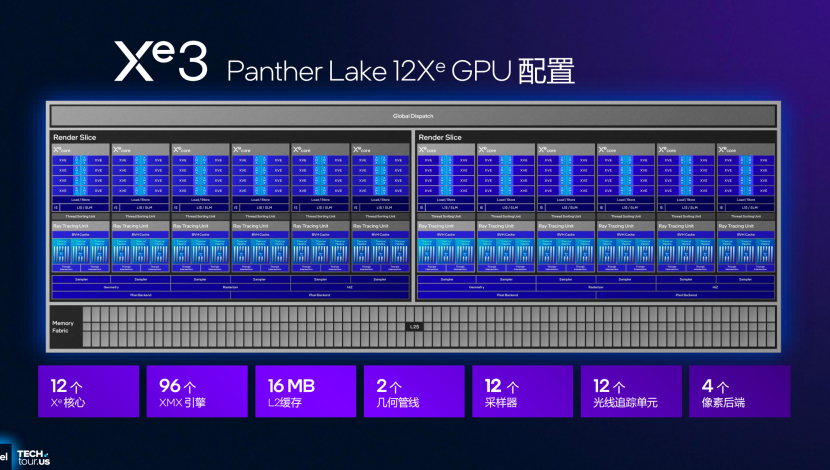
首先渲染切片(Render Slice)由Xe2的4 Core/Slice扩展为6 Core/Slice,最大12 Xe-Core规格包含XMX引擎96个、RTU 12个;共768个XVE(512-bit SIMD16与96个 2048-bit XMX,理论FP16/BF16算力达到120 TOPS。
并且支持不同规格的GPU Die的设计,不同的厂商可以根据不同的算力需求进行自由搭配,芯片的设计也更加灵活,
XMX支持INT4/INT2,配合OpenVINO-NNCF可在6 ms内完成7B-parameter LLM首次 token生成,针对端侧的AI计算能力,提升非常巨大。
另外在新的Xe-Core 内部,第三代 XVE 矢量引擎将线程槽由64增至80,并发线程数提升25%;寄存器文件采用可变粒度分配,FP32与INT32混算场景利用率提升18%。XMX 矩阵引擎新增2048-bit共享加载/存储路径,保证FP8权重反量化与INT4稀疏计算无阻塞。

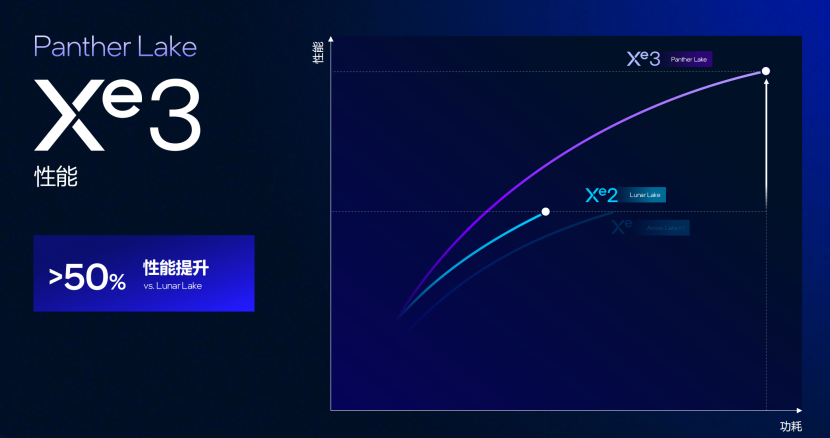
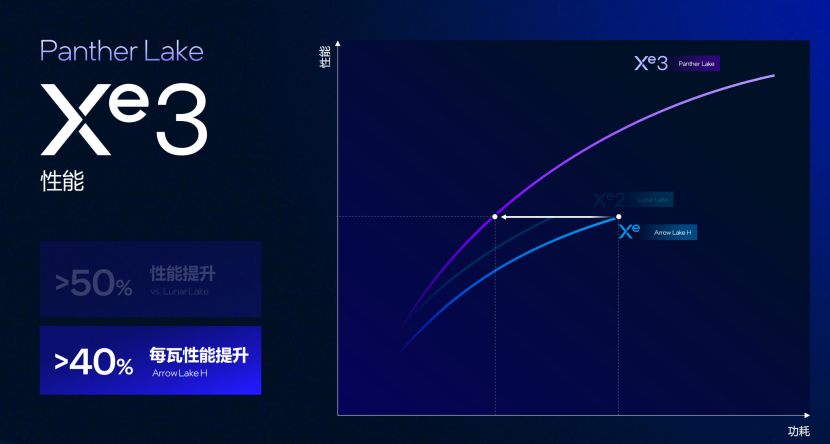
几何前端引入双异步几何管线,每周期可递交6个三角形网格,与12个RTU 形成1:2的吞吐配比,性能相对于上代提升50%,并且每瓦的功耗降低了40%。

除了对于AI性能的提升巨大之外,Panther Lake这次的Xe3架构对于游戏和光追性能的表现也提升巨大,并且还支持XeSS。
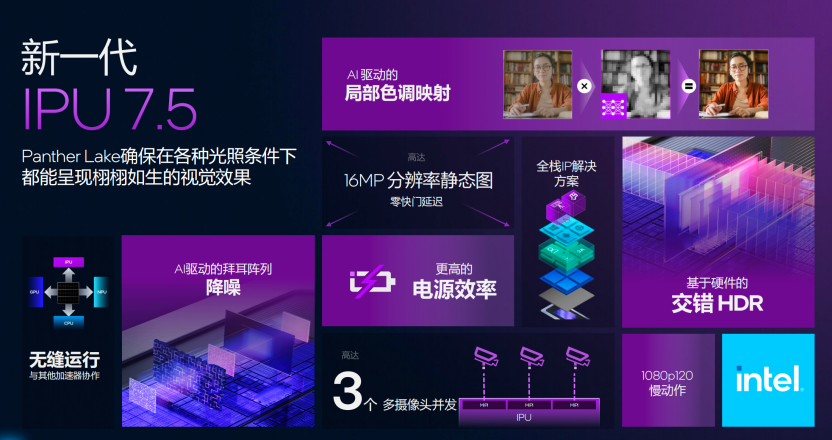
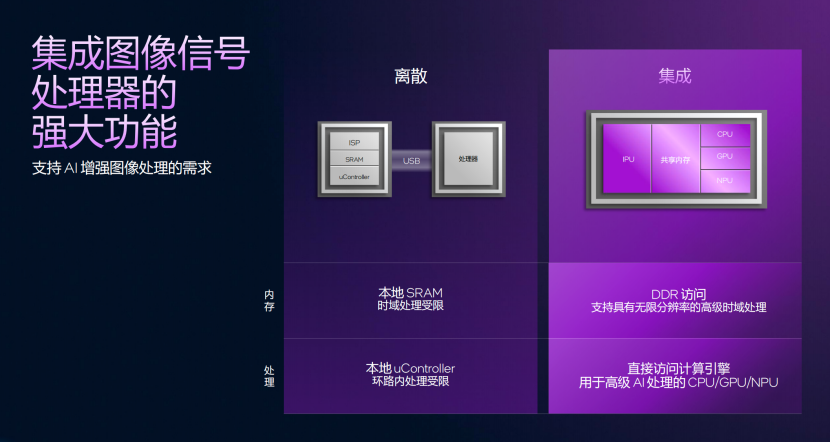
集成式IPU:图像处理单元的进一步优化
在全面升级的显卡加持下,全新的Panther Lake搭载的新一代的IPU更是让图像处理功能获得了跃升。用户可以在各种光照条件下,都能够呈现栩栩如生的视觉效果,并且这次的Panther Lake搭载的IPU拥有了全新的功能,首先是增强型的HDR,带来更宽的动态范围,二是基于AI的视频和图片降噪功能,通过NPU或者GPU处理之后,在集成的IPU内进行输出,噪点被处理地非常好,第三就是AI驱动的局部色彩映射功能,通过AI驱动的参数调节,改善照片的对比度,最终实现保证图片色彩的表现,在弱光环境下,实现更好的图片显示效果。


上面左侧这张RAW图像是通过传感器直接采集到的,看上去非常模糊不清,对比度差,且有很多噪点。但是经过Panther Lake的ISP处理之后,可以看到右侧的成片质量非常高,从一张昏暗模糊的废片,直接变成了一张清晰、色彩饱满的成片,ISP的表现非常出色的。
并且这次Panther Lake使用了集成式的IPU,相比较离散的解决方案,拥有更大的优势,可以和系统共享内存,并且支持无限分辨率的高级时域处理。

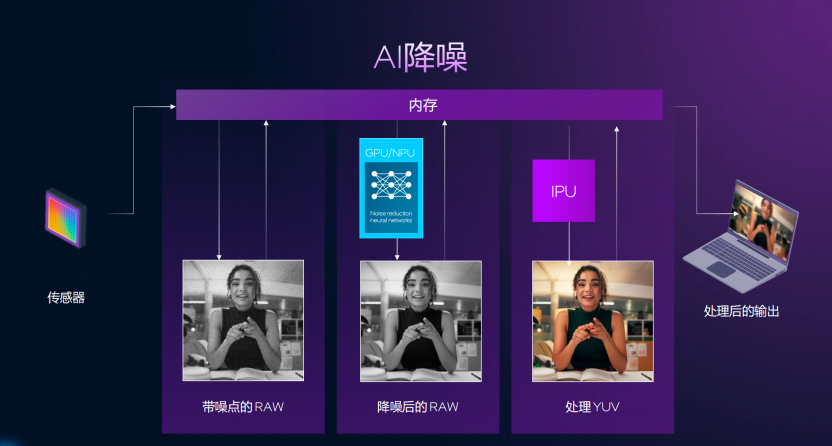
这次全新的ISP在硬件加速,功耗表现上,都更为出色,并且对于需要经常开会的同学来讲的话,配合上一款不错的传感器,能够实现更好的AI视频降噪效果,带来更为出色的视频会议画面,并且AI换背景、AI画质增强等,都轻松应对,即便是弱光环境也能带来优秀的视频画面。
另外对于内容创作与AI生产力的用户来讲,Panther Lake搭载的全新的视频编解码器,在DaVinci Resolve的8-bit 4:2:0 4K视频导出方面,Xe3的XeMedia Engine 双编解码器并行,耗时4分12秒,较上一代缩短38 %,优于 Apple M3的6分05秒。

Wi-Fi 7 R2 + BT 6.0:连接子系统的AI感知演进
随着云端协同的AI模型在快速发展,网络连接在这个过程中有着纽带的关键作用,直接决定了数据交换的效率,以及结果的生成速度,为了满足未来AI应用应用的发展,这次英特尔的Panther Lake在底层WiFi和蓝牙架构设计方面,在高负载以及以及多重并发数据交换上,进行了加强,满足AI时代的数据连接要求,并且为整个PC无线连接行业做了新的标杆。

作为PC行业无线连接标准的制定者和参与者,英特尔已经在20余年的时间内主导参与并制定了从WiFi 4-WiFi 7所有的方案,拥有完整的全方位的PC无线连接解决方案,并且携手无线模块厂商、ISV,做封装、开发和测试,对行业和用户都有非常深刻的影响。


首先Panther Lake内部集成BE211 CRF模组,拥有320 MHz/4K-QAM/MLO三频并发能力,新增单链路eMLSR、P2P 信道协同、限定TWT,整体的传输速度更快,能耗更低。
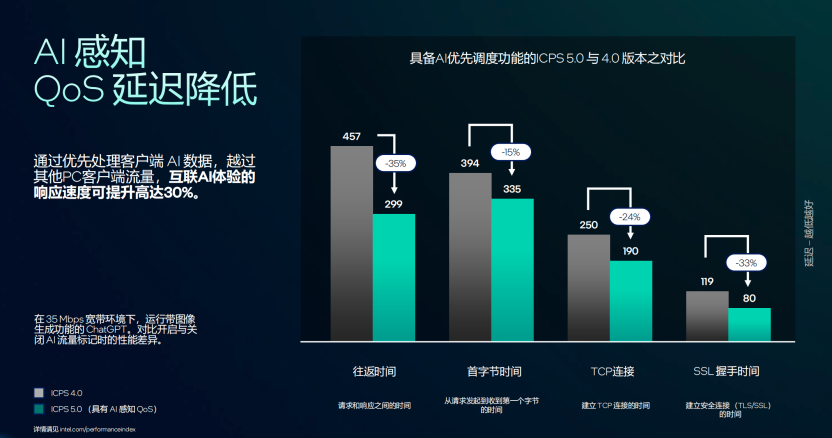
并且为了满足AI大模型的更快的数据交换和响应,这次的Panther Lake新增了AI感知的QoS技术,ICPS 5.0在驱动层加入2-class队列调度,以30 Hz频率实时检测AI流量特征(token-rate、burst-length、SLA 预算)。
当识别到生成式AI应用(Copilot、Stable Diffusion)的时候,软件驱动把对应的TCP/UDP 流标记为AC_VO+,获得6ms抢占窗。35 Mbps外网、512-token长度下,首包延迟下降35 %,SSL握手缩短33 %,整体AI响应速度提升30%。
全新的蓝牙 6.0 新增Auracast功能,为下一代PC连接打下基础

英特尔全新的Panther Lake使用了目前最新的蓝牙6.0技术,对于PC用户来讲,在音频方面,能够实现更强、更稳定的连接表现。

这一次Panther Lake将WiFi和蓝牙的MAC部分集成在系统的平台芯片。中间通过高达11Gbps的CNVio 3接口连接,有效降低了无线模块的芯片面积,也改善了散热,且通过减少WiFi模块的芯片面积,也在Wi-Fi模块上集成了多Core的蓝牙模块。
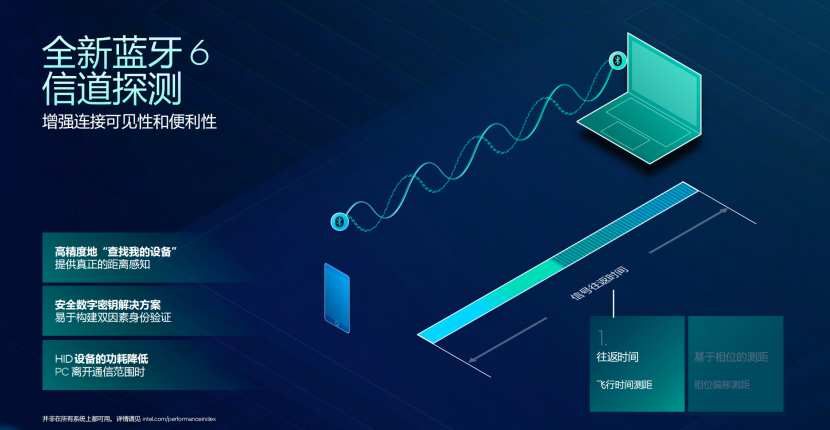
蓝牙6.0技术传输速度更快,对于游戏玩家来讲,能够有效降低游戏音频的延迟,游戏体验更好,并且更高速率的音频采样,对于观影和音乐用户来讲,可以实现出色的立体声和多流音频表现,并且更低的功耗表现,也能够让蓝牙设备的续航时间变得更长,而PC的使用时间也同时可以变得更长,实际的使用体验,实现更为明显的提升。
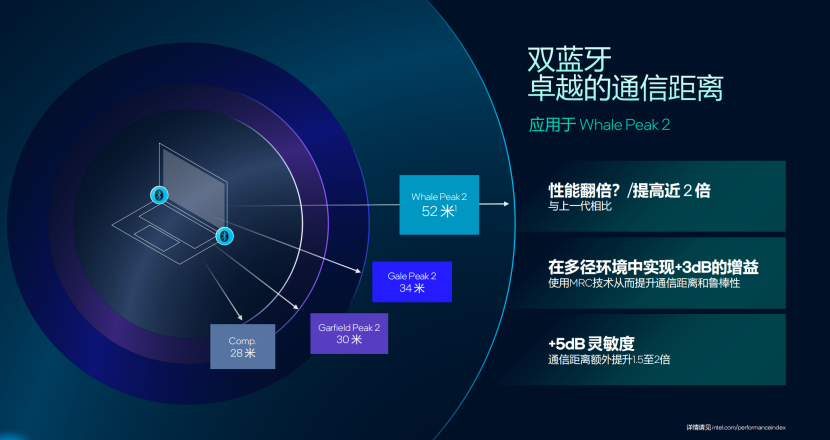
并且搭载英特尔Panther Lake的PC还有双蓝牙的功能,在整体的性能方面,相对于上代实现2倍的提升,长距离的连接表现上面,更加稳定,比如说Whale Peak 2可以达到52米的通信距离,也可以提供高达+5db的灵敏度,并且配合上厘米级的定位表现,让我们在查找物品的时候,可以实现精准定位,并且这次Panther Lake的PC还拥有“Auracast”功能,能够利用广播音频将音频分享给身边的朋友或者扬声器,让用户共享美妙声音,并且还有辅助助听器的功能。
另外,无线WiFi 7和蓝牙 6.0配合上Panther Lake推出的全新的无线软件套件功能,同样具备高级蓝牙监控,具备AI高质服务质量的QoS,还有增强型的流量优先级,将语音、视频的延迟同时降低70%,也可以将视频分辨率提升4倍,改善网络拥堵的情况,也为AI生成的连接和SSL握手时间降低,时间最高可以缩短35%,为生成式AI的网络需求,提供更优秀的支持。
写在最后:
Panther Lake通过18A制程、RibbonFET、PowerVia与Foveros-S实现1.3×晶体管密度、25 % 同频功耗下降;Xe3-LPG在15 W 级交付120 TOPS AI与50 %图形性能,性能堪比独立显卡;Wi-Fi 7 R2与BT 6.0把无线延迟压到5 ms级,并以AI感知QoS保障生成式应用30 %响应提速。CPU 10 TOPS + NPU 50 TOPS + GPU 120 TOPS的180 TOPS超强算力,满足高性能AI PC的标准,更进一步加速AI PC的普及。
在即将到来的CES 2026上,英特尔将正式发布酷睿Ultra处理器(第三代)(Panther Lake家族)。随着18A的全面量产,AI PC 渗透率有望从2025年的15 %提升到2026年的55 %。Panther Lake不是简单的制程迭代,而是英特尔为AI PC时代重绘的客户端计算与连接基准。

