【IT168 资讯】5月27日,在北京中关村皇冠假日酒店的多功能大厅,AMD的副总裁Joe Macri先生和AMD资深技术院士Dan Bouvier先生为我们解开了第六代APU产品的神秘面纱。全新的挖掘机构架和突破性的全面升级让处理器的历史再一次发生了变化。

▲AMD第六代处理器
Carrizo是AMD第六代A系列APU的代号,使用真正的系统级芯片(SoC)设计。AMD在上一代的部分入门级产品中使用过这种设计,比如说Kabini、Beema。现在是首次在高性能产品上应用SoC设计。AMD新一代Carrizo APU跟上一代Kaveri APU一样采用28nm制程,拥有4个挖掘机核心,它是目前CPU核心性能最高的产品。另外,Carrizo还有8个GPU核心,也是第一款完全支持HSA1.0规格的处理器,它有3个显示引擎、3个DDI端口。

▲AMD的副总裁Joe Macri先生和AMD资深技术院士Dan Bouvier先生
AMD在产品设计方面有三个目标:大幅度提升电池续航时间;在视频、游戏和GPU计算等方面保持领先;提升CPU核心性能。整个系统级芯片(SoC)的关键就是提升CPU核心性能,它能够提升每瓦性能。AMD不仅在调整设计工艺,同时也在做基础性设计方面的调整。

▲Carrizo设计目标
◆降低2.4倍的功耗和提升1.5倍的性能
大家在使用电脑的时候,不仅希望性能强大,也同样希望手中的笔记本能够带来出色的低功耗表现。在这一代产品上达到了2倍左右功耗降低,以及1.5倍左右的性能提升。续航在移动使用日益主流的今天显得尤为重要。通常一款处理器想要提升自己的性能势必会牺牲一些能效上的表现,而第六代APU做到了两者之间完美的平衡。
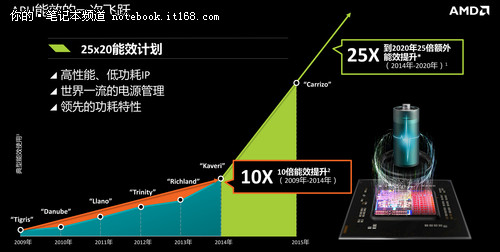
▲能效的飞跃
2倍的功耗降低,并且性能也跟着提升了1.5倍,这是如何做到的?想要解开这个科技密码我们不得不先说起全新的“挖掘机”构架。挖掘机是AMD用于Carrizo产品上的新一代X86核心的代号。对比上一代压路机的核心硅片面积,挖掘机的硅片面积减少了很多。(压路机是用于上一代Kaveri APU产品上X86核心的代号)
一般来说,如果要实现这样的面积减少,可能需要去迈入下一个制程节点,但AMD还是留在28nm制程上,这意味着如果减少尺寸,可能会降低性能,但实际上Carrizo性能并没有减少,反而增加了。这是怎么做到的呢?
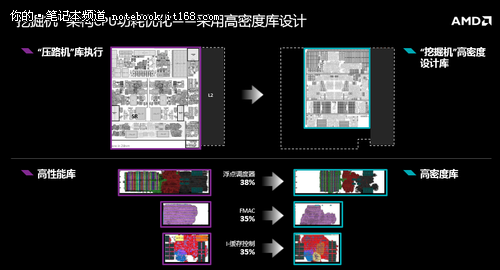
▲挖掘机采用高密度库设计
2012年,AMD在做架构设计的时候,发现了GPU在引擎处理方面的一些工艺、技术,实际上是有可迁移性的。比如说晶体管的装配方式,是可适用于CPU核心的。所以AMD在CPU核心上做了一些实验,拿到现在的产品。这意味着AMD可以用更高密度的“晶体管库”形式的设计,减少核心面积。
通过工艺改造,能够把核心面积缩小约26%到35%。由于面积更小,所以这些晶体管之间的距离就更紧凑,如果能够提高每时钟周期指令数,在运算过程中就能够降低功耗。
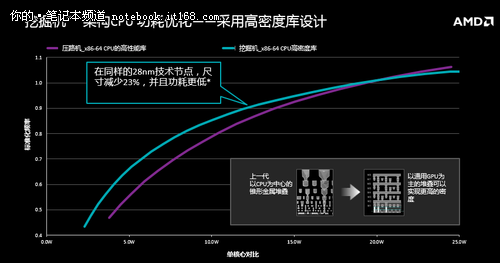
▲两代构架功耗对比
了解了功耗是如何降低的,我们再回过头来看看性能是如何提升的。首先,Carrizo提升了缓存的性能,增加了一倍的一级数据缓存的面积,在上一代这是设计方面的瓶颈。第二,Carrizo拥有更好的分支预测,能够在CPU核心上对于下一波要来的数据量做智能化预测。通过这样的优化,能够减少CPU等待数据时间,提高整体性能。
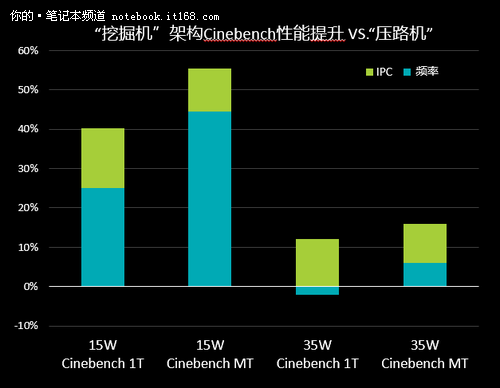
▲性能提升对比
第三,Carrizo降低了二级缓存的延迟时间,从原来的19时钟周期降到了18时钟周期,大概提升一个时钟周期的延迟时间。此外,Carrizo还加强了分支预测的准确性,分支预测是影响功耗的重要因素。AMD希望分支预测更加理性,不会做大量的无用功去执行错误或无效的分支预测,在这个过程中,就能够提高性能。
◆视频应用的显著提升
对于大部分的PC用户来讲,视频是一个非常重要的应用方面,因为大家用PC可能会看视频内容、制作视频、开视频会议等等各种各样的应用。视频部分AMD也是着眼于能效的提升,CPU核心方面的优化设计,在视频加速方面也得到了应用。
AMD引入了UVD 6统一视频解码器,支持最新的HEVC H.265(现场演示中竞品并不能流畅播放同样的视频片段)。AMD对视频的播放流程进行了优化,UVD 6拥有4倍于上代产品的解码带宽,能够在更短的时间里处理更多帧的画面,从而加大处理器的空闲时间,大幅度降低了笔记本在播放视频时的功耗,给笔记本带来了更持久的续航时间。根据AMD的数据,Carrizo能够拥有8.3小时的高清视频播放时间。
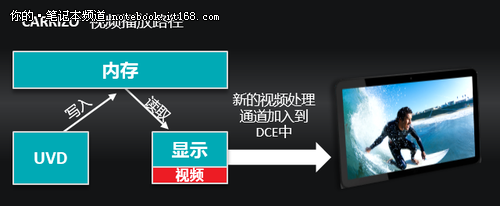
▲视频播放路径
在图形显示方面,AMD是把GPU图形核心的硬件设计理念,沿用到了显示核心方面,在此基础上,能够实现更优化的视频播放,并且功耗更低。因为在视频播放的时候,在后台会有一个额外的视频处理通道,确保视频播放能够更有效的执行,AMD称这个新的通道为底层支持(Underlay support)。
根据整条的传输路径,从UVD到显卡,再由显卡到显示器,视频可以有两种不同的处理方式。可以把原始视频内容的分辨率进一步扩大,增大图像分辨率。也可以对原始视频进行压缩,降低图像的分辨率,这两种视频格式都可以输出。
只通过显示处理器,而不通过图形处理器,就能够把1080P的视频上扩为4K的视频。所以效果是非常显著的。在Carrizo APU播放1080P的视频时,可以实现超过500mW的功率节省。这种技术相信在不久的未来将彻底改变人们的视频体验。
◆“Carrizo” GCN架构和HSA加速功能
Carrizo有8个第三代GCN核心,能够实现819 GFLOPS的运算速度,512KB的共享二级缓存,更优化的曲面细分性能。支持DirectX12,最大的创新就是能够充分利用CPU核心的能力,将GPU核心的性能提升到前所未有的水平。另外也新增了一些指令集,这一部分不会展开讲,基本上是增加了16位float指令集,通过增加指令集进一步优化CPU和GPU之间的共享。
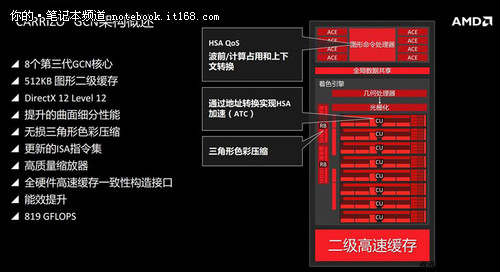
▲Carrizo有8个第三代GCN核心
另外再说一说HSA的加速功能。可能很多人士头一回听说这个名词,它究竟具体是什么?说白了它就像是一个非常高效的处理机制,能够让所有的运算单元共享虚拟的存储空间。
HSA在性能提升方面增加了缓存的面积,可以更好地利用GCN核心。内存是有一致性的,一致性的意思是说内存一方面读取,一方面写入,而读取和写入的数据是一样的,不会出现偏差,也不会通过读取和写入处理旧数据。
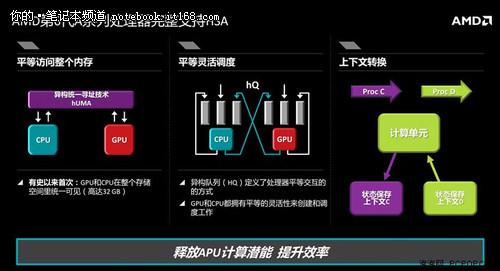
▲完整支持HSA
那么CPU跟GPU的核心如何协同工作呢?在共享内存的情况下,如何处理不同的工作内容,比如说CPU负责写,GPU负责读,这要确保处理的数据是一致的,不会出现偏差。大家知道在程序运行的过程中有不同的进程,可能第一个的进程上下文切换还没有完成,就又开始了一个新的进程。所以要确保不管是一个CPU核心,还是一组CPU核心,要有一个有条不紊的共享和切换。
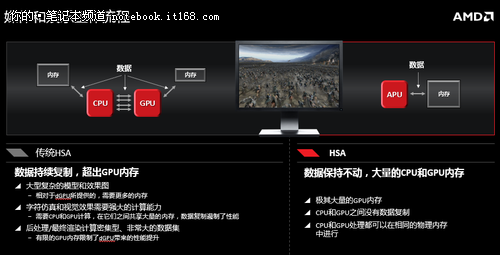
▲媒体和娱乐工作流程
在HSA架构中把上下文转换引入到了GPU核心中。GPU有两类处理任务,一类图形,一类是图形计算。图形的上行下行数据是非常巨大的,存储需要很长时间,所以AMD把这一部分任务空间释放,进行图形计算,AMD把它叫做“任务预抢占”。在图形计算方面,上下文转换的数据是比较小的,所以可以像在CPU核心中一样,把它们进行存储,让所有的GPU计算共享GPU的核心。

▲制造业的建设工作流程
总结:Carrizo能够在28纳米制程上继续创造降低功耗并提升性能的奇迹的确是非常了不起,我们可以清晰的看出Carrizo对于笔记本带来的提升是多么巨大。我们期待AMD能够继续为科技带来更多的变革。这次的第六次APU全面升级不仅仅是一次简单的提升,而是一次概念的转变,影响笔记本市场和人们认知的转变。
更多精彩内容请扫描下方二维码!


